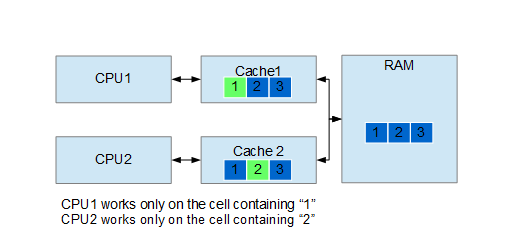
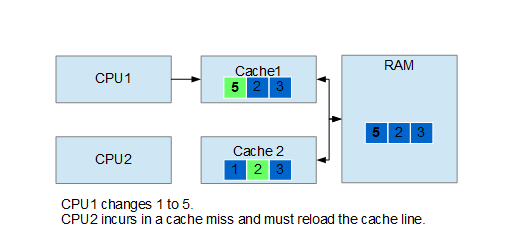
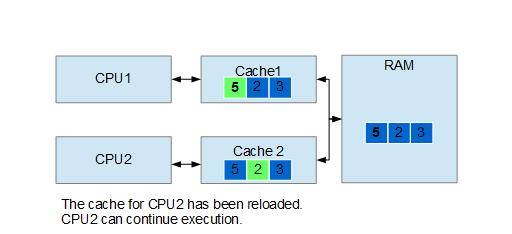
C++17 introduced std::string_view to allow manipulating strings without the overhead of heap allocation coming from std::string. In this article we will see a couple of use cases.
First and foremost, what is string_view? It is a non-owning view over a contiguous sequence of chars. Let’s unpack the definition:
- View: you have read-only access and you might be restricted to a sub-sequence of the original sequence;
- Non-owning: something else owns the memory you can read from.
Return a string_view
When should we return string_view instead of string? Let’s see some examples:
class Employee{
std::string id;
public:
const std::string& getID() const{return id;}
};
Should we switch the return type of getID from string to string_view? No. We have already a string, we can simply return a reference to the string. The user of your class will see the return type and they should know that they must ensure that the instance of employee lives longer than the reference.
Let’s now add a fallback value to the ID:
const std::string& getId() const {
if(....)
return id;
return "ID NOT AVAILABLE";
}
This is BAD! Because if you return the string literal "ID NOT AVAILABLE" , the returned reference will bind to an instance of string local to the function getId. The caller will therefore obtain, a dangling reference. Welcome to the beautiful world of Undefined Behavior.
Before C++17 we have various solutions to the issue:
- Always return
stringinstead of a reference and incur in the memory allocation penalty; - Create a static
stringinstance containing the string literal and return a reference to thestringin the second return - Return
const char *, but this can be done only if you assume thatiddoes not contain termination characters between other chars. (See the notes at https://en.cppreference.com/w/cpp/string/basic_string/c_str )
In C++17 we can fix the situation in a very elegant way: we can notice that both the possible return values will survive after the end of the call. So we can rewrite the function as
std::string_view getId() const {
if(condition)
return id;
return "ID NOT AVAILABLE";
}
We used an if/else, let’s use a conditional expression instead to have more compact code.
std::string_view getId() const {
return condition ? id : "ID NOT AVAILABLE";
}
And this is also BAD, as the author of this question on stackoverflow discovered. Why? I will shamelessly summarize the accepted answer . What is the type of the expression? To decide its return type, the expression tries to convert one of the two types (say the string literal for example) to the other (the std::string) and it manages to exactly this conversion! Basically you get something like:
std::string_view getId() const {
std::string temp = condition ? id : "ID NOT AVAILABLE";
return temp;
}
Which is bad because you will be returning a string_view pointing to a temporary which is destroyed when the function returns. The solution? We need the target type to be a string_view, we have a nice conversion available between string and string_view, so let’s nudge the expression in the right direction transforming the string literal in a string_view:
std::string_view getId() const {
return condition ? id : std::string_view{"ID NOT AVAILABLE"};
}
Another example of return value is getting a substring, consider the following member function of the class Employee:
std::string getPartOfId(const std::size_t n) const{
return id.substr(0, n);
}
This is so wasteful: id will survive the end of the call but we are creating a new string for no good reason.
In C++17 we could write this:
std::string_view getPartOfId(std::size_t len) const {
std::string_view view{ id };
return view.substr(0, len);
}
If the end user needs a string, they can still convert the string_view to a string, but the function is not doing any potentially useless allocations.
But is all of this worth it? Yes, we did some tests, using relatively long substrings (40 chars) to avoid small string optimizations and we used both versions of getPartOfId . The string_view version was up to 6 times faster on MSVC 2019 using optimization O2 than the version return a string.
So, let’s summarize, when is appropriate to use string_view as a return value?
- When we would need to build a
string - We can be sure that the
string_viewwill not exceeds the lifetime of the memory it depends on
Use string_view as input parameter
Let’s add yet another member function to our class
void appendToId(const std::string& newPart) {
id += newPart;
}
If we pass to appendToId a string literal, a temporary string will be created, passed to the function, and then destroyed. This is wasteful, in particular is the string literal is so long that the small string optimization cannot be used. But with a small change we can do the following:
void appendToId(std::string_view newPart) {
id += newPart;
}
And we can avoid a wasteful heap allocation.
So string_view is a sure winner as input parameter, no? Well, not really, string_view can be a barrier for optimization, consider this last member class of Employee:
void setId(std::string id){
id = std::move(id);
}
Passing by value has advantages: assume that the user of the function does not need anymore the input parameter, they can simply invoke the function as:
employee.setId(std::move(newID));
giving up the buffer that the string owns. This also works if you pass a string literal because a new string will be created on-the-fly and then, inside the function, the underlying buffer can be moved inside id. On the pro, cons and alternatives to this approach, you can refer to The Nightmare of Move Semantics for Trivial Classes, a CppCon2017 presentation by Nicolai Josuttis.
Null termination and C-style functions
Assume we have a string_view and we have a c-style function accepting a null-terminated character array, something like:
strlen(const char*)
Is it safe to invoke the function in this way?
std::string_view s = .....
....
strlen(s.data())
No! Because string_view might not be null-terminated: see, for example the case where s is the result of the invocation of substr on a string_view.
Conclusion
string_view allow for expressive and performant code but at a risk: the user of the class must be aware of the lifetime implications and we must be mindful of the fact that string_view is not guaranteed to be null-terminated. Secondly, the use as input parameter makes sense when the function could not benefit from passing by value the input parameters.