Few days ago I was listening to a talk from Michael Wong at ACCU 2019, when he mentioned that C++17 has false sharing support, at around 01:05:00.
Some of the comments pointed out a new nifty feature of the C++17 standard: https://en.cppreference.com/w/cpp/thread/hardware_destructive_interference_size
The last time I dealt with false sharing I was using C, OpenMP and some hard coded values. Let’s see if C++17 makes our life easier.
False Sharing
A bit of background first, if you know what false sharing is, skip to the next section.
Let’s first discuss the Sharing part of False Sharing: when reading data from the RAM, the CPU loads a block of memory (cache line) in its own cache (actually there are more cache levels, but let’s ignore this fact). This is done to leverage data locality: if you access a piece of data, most likely you will access other pieces of data that are close to it, so it makes sense to load the whole cache line into the cache for faster retrieval. What happens when one CPU modify the content of a cache line currently shared with other CPUs? The caches of the other CPUs must be reloaded before the processes running on those CPUs can continue, stalling them. This mechanism allows the various threads of execution in a process to have a coherent view of the memory. Intel has a nice article about the issue where you can get more details.
Now let’s discuss the False bit of False Sharing: this happens when two or more processes read and modify independent data on the same cache line. In this case the cache coherence mechanism we saw before becomes an issue: a CPU stalls waiting for an update that is completely useless. See the example below.
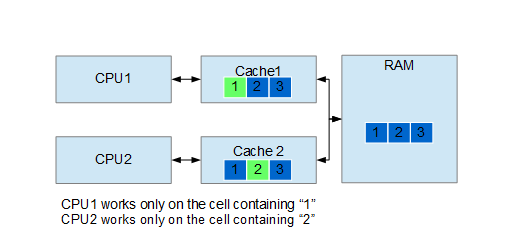
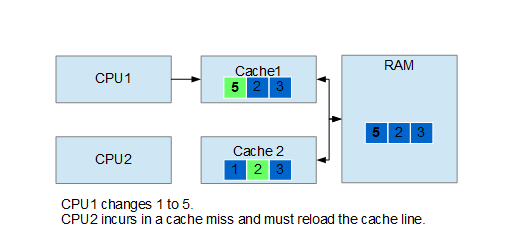
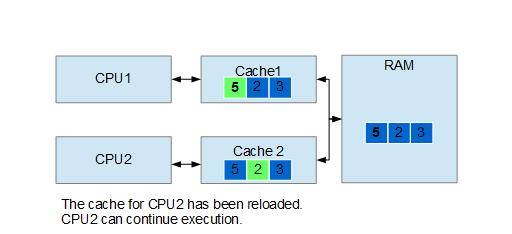
False sharing can be fixed, usually, in two different ways:
- Make sure that unrelated data are stored in different cache lines
- Use local data for intermediate calculation and then access shared memory only at the end.
Usually, my favorite solution is the second, but what happens when only the first can be pursued? C++17 to the rescue!
False Sharing and C++17
The header <new> in C++17 comes with a new constant:
#include <new>
inline constexpr std::size_t
hardware_destructive_interference_sizeYou can use this constant to make sure that independent data belongs to different cache lines because the variable allow us to access the size of a cache line in a portable way. Consider
struct resultType {
int val;
};An array of resultType might have false sharing: for example, if int is 4 bytes and a cache line is 64 bytes, up to 16 consecutive cells of the array will fall in the same cache line. We can change the struct in this way:
struct resultType {
alignas(hardware_destructive_interference_size)
int val;
};Now every struct will add enough padding to make sure that every val element has its own cache line. This, in theory, will avoid false sharing but we have to pay a cost: because of the alignment requirement the struct will increase its size.
Measure, measure, measure
Any optimization must be tested. At the time of writing only Microsoft Visual Studio 2019 supports this feature. I made some evaluations using the following test environment:
- Microsoft Visual Studio 2019, Community, version 16.1.1
- Optimization level: O2
- Build: Release / x64
- Standard: C++17
- Processor: Intel i7-4800MQ
- RAM: 16 GB
Below the program I used in my experiments. Please note that if you find yourself dealing with a similar problem, using raw threads as I did is a very bad idea, please consider using std::future or at least local variables (more on this below).
#include <algorithm>
#include <iostream>
#include <numeric>
#include <chrono>
#include <thread>
#include <array>
#include <new>
#define FALSE_SHARING() false
int main() {
constexpr std::size_t numProcessors = 2;
constexpr std::size_t numIter = 40'000'000;
#if FALSE_SHARING()
std::cout << "With false sharing \n";
struct resultType {
int val;
};
#else
std::cout << "Without false sharing\n";
struct resultType {
alignas(std::hardware_destructive_interference_size) int val;
};
#endif
std::array<resultType, numProcessors> results{ 0 };
std::array<std::thread, numProcessors> threads;
auto start = std::chrono::high_resolution_clock::now();
for (std::size_t i = 0; i < numProcessors; ++i) {
auto& result = results[i];
threads[i] = std::thread{ [&result, numIter]() {
for (std::size_t j = 0; j < numIter; ++j)
result.val = (result.val + std::rand() % 10) % 50;
} };
}
std::for_each(begin(threads), end(threads), [](std::thread & t) { t.join(); });
auto stop = std::chrono::high_resolution_clock::now();
std::cout << "Duration "<<std::chrono::duration_cast<std::chrono::milliseconds>(stop -
start).count() << '\n';
const auto res = std::accumulate(cbegin(results), cend(results), resultType{ 0 },
[](const resultType a, const resultType b) {
auto s = a.val + b.val;
return resultType{ s };
});
std::cout << "result " << res.val << '\n';
}
The results for 2 threads of execution are as follows:
| No False Sharing (ms) | False Sharing (ms) |
| 880 | 1853 |
| 768 | 1648 |
| 764 | 1642 |
| 761 | 1743 |
| 754 | 1576 |
| 772 | 1591 |
| Average: 783 | Average: 1675 |
So, now, thanks to C++17 we can avoid false sharing without having to hardcode values or use platform-specific macros.
In this particular case, I would advise against using the alignment trick, I would suggest using local variables as much as possible. If we substitute the central loop with the following construction, where all the intermediate calculation are done on the local variable localRes:
for (std::size_t i = 0; i < numProcessors; ++i) {
auto& result = results[i];
threads[i] = std::thread{ [&result, numIter]() {
resultType localRes{0};
for (std::size_t j = 0; j < numIter; ++j)
localRes.val = (localRes.val + std::rand() % 10) % 50;
result = localRes;
}
};
}we minimize the false sharing to the final assignment and the two version of the code yield basically the same results.
Closing Notes
False sharing can be an insidious problem that can hinder the performance of multi-threaded code. In the past the only weapons at our disposal were the use of local data or hardcoding the cache line size, making the code less portable. Now thanks to C++17 we can obtain information about our cache in a portable way.

One thought on “C++17 and False Sharing”